
We redesigned the AI Crawl Control dashboard to provide more intuitive and granular control over AI crawlers.
- From the new AI Crawlers tab: block specific AI crawlers.
- From the new Metrics tab: view AI Crawl Control metrics.
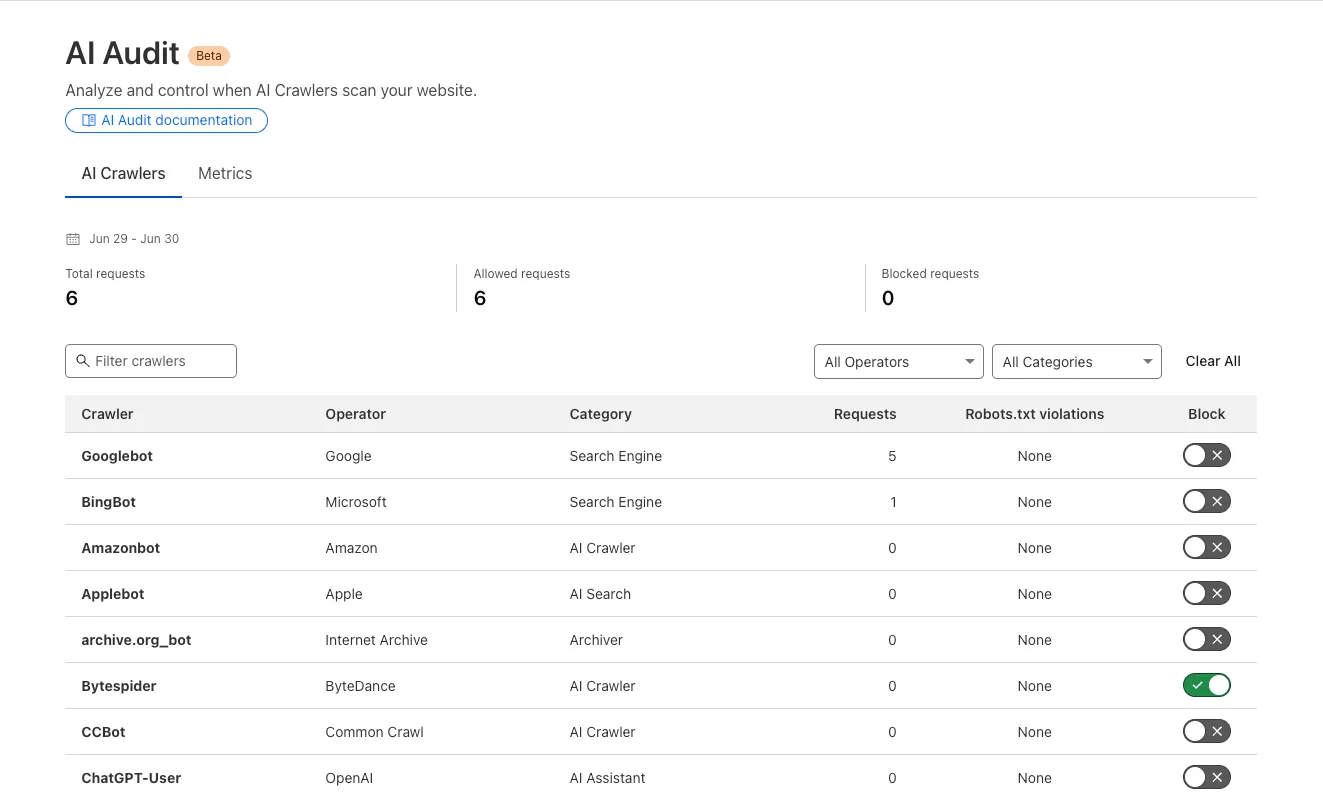
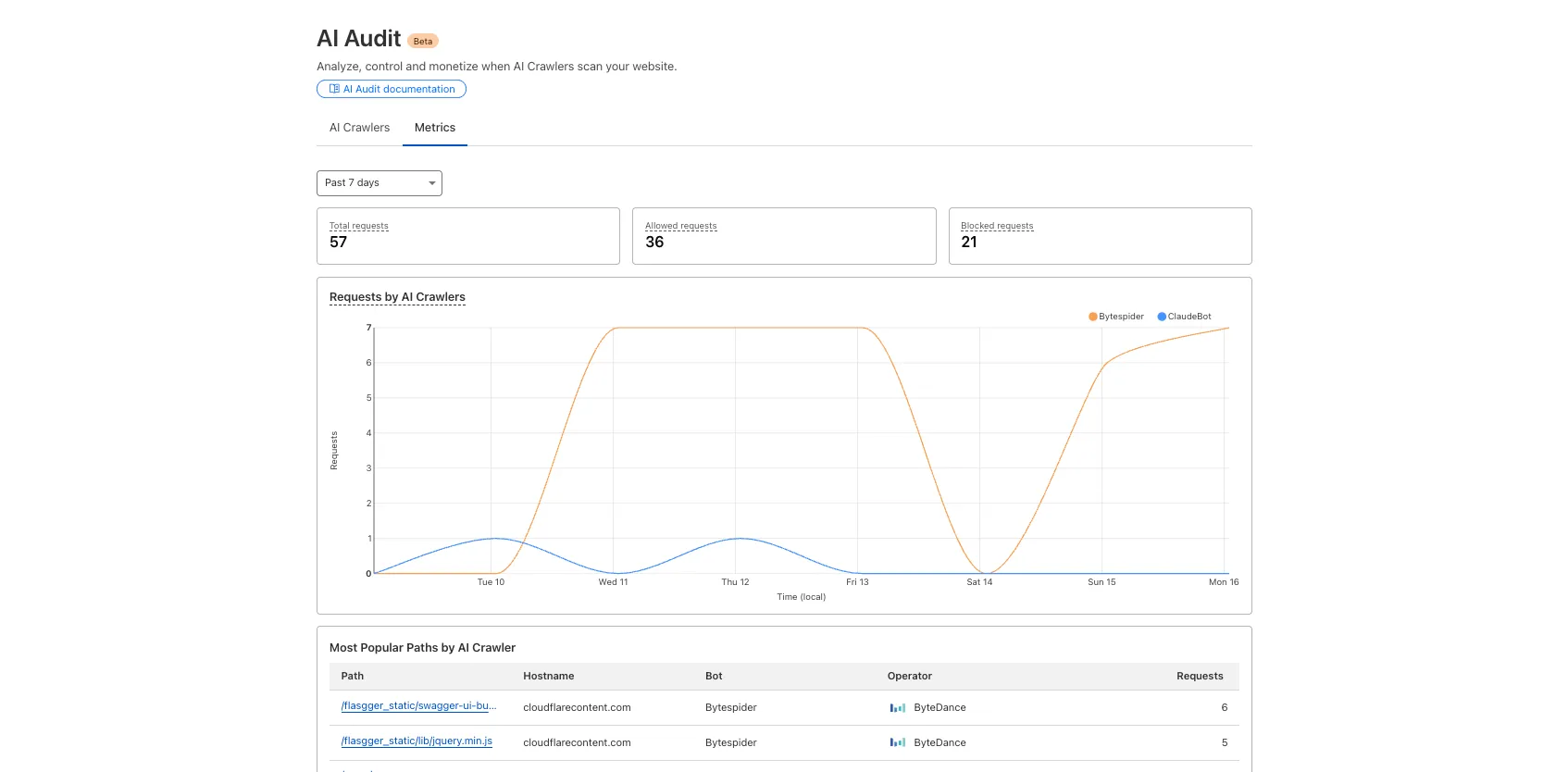
To get started, explore:
-
Radar now offers expanded insights into web crawlers, giving you greater visibility into aggregated trends in crawl and refer activity.
We have introduced the following endpoints:
/bots/crawlers/summary/{dimension}: Returns an overview of crawler HTTP request distributions across key dimensions./bots/crawlers/timeseries_groups/{dimension}: Provides time-series data on crawler request distributions across the same dimensions.
These endpoints allow analysis across the following dimensions:
user_agent: Parsed data from theUser-Agentheader.referer: Parsed data from theRefererheader.crawl_refer_ratio: Ratio of HTML page crawl requests to HTML page referrals by platform.
In addition to crawler-specific insights, Radar now provides a broader set of bot endpoints:
/bots/: Lists all bots./bots/{bot_slug}: Returns detailed metadata for a specific bot./bots/timeseries: Time-series data for bot activity./bots/summary/{dimension}: Returns an overview of bot HTTP request distributions across key dimensions./bots/timeseries_groups/{dimension}: Provides time-series data on bot request distributions across the same dimensions.
These endpoints support filtering and breakdowns by:
bot: Bot name.bot_operator: The organization or entity operating the bot.bot_category: Classification of bot type.
The previously available
verified_botsendpoints have now been deprecated in favor of this set of bot insights APIs. While current data still focuses on verified bots, we plan to expand support for unverified bot traffic in the future.Learn more about the new Radar bot and crawler insights in our blog post ↗.
You can now use any of Vite's static asset handling ↗ features in your Worker as well as in your frontend. These include importing assets as URLs, importing as strings and importing from the
publicdirectory as well as inlining assets.Additionally, assets imported as URLs in your Worker are now automatically moved to the client build output.
Here is an example that fetches an imported asset using the assets binding and modifies the response.
TypeScript // Import the asset URL// This returns the resolved path in development and productionimport myImage from "./my-image.png";export default {async fetch(request, env) {// Fetch the asset using the bindingconst response = await env.ASSETS.fetch(new URL(myImage, request.url));// Create a new `Response` object that can be modifiedconst modifiedResponse = new Response(response.body, response);// Add an additional headermodifiedResponse.headers.append("my-header", "imported-asset");// Return the modfied responsereturn modifiedResponse;},};Refer to Static Assets in the Cloudflare Vite plugin docs for more info.
A new GA release for the Windows WARP client is now available on the stable releases downloads page.
This release contains improvements and new exciting features, including SCCM VPN boundary support and post-quantum cryptography. By tunneling your corporate network traffic over Cloudflare, you can now gain the immediate protection of post-quantum cryptography without needing to upgrade any of your individual corporate applications or systems.
Changes and improvements
- Fixed a device registration issue that caused WARP connection failures when changing networks.
- Captive portal improvements and fixes:
- Captive portal sign in notifications will now be sent through operating system notification services.
- Fix for firewall configuration issue affecting clients in DoH only mode.
- Improved the connectivity status message in the client GUI.
- Fixed a bug affecting clients in Gateway with DoH mode where the original DNS servers were not restored after disabling WARP.
- The WARP client now applies post-quantum cryptography end-to-end on enabled devices accessing resources behind a Cloudflare Tunnel. This feature can be enabled by MDM.
- Improvement to handle client configuration changes made by an MDM while WARP is not running.
- Improvements for multi-user experience to better handle fast user switching and transitions from a pre-login to a logged-in state.
- Added a WARP client device posture check for SAN attributes to the client certificate check.
- Fixed an issue affecting Split Tunnel Include mode, where traffic outside the tunnel was blocked when switching between Wi-Fi and Ethernet networks.
- Added SCCM VPN boundary support to device profile settings. With SCCM VPN boundary support enabled, operating systems will register WARP's local interface IP with the on-premise DNS server when reachable.
- Fix for an issue causing WARP connectivity to fail without full system reboot.
Known issues
For Windows 11 24H2 users, Microsoft has confirmed a regression that may lead to performance issues like mouse lag, audio cracking, or other slowdowns. Cloudflare recommends users experiencing these issues upgrade to a minimum Windows 11 24H2 version KB5060829 or higher for resolution.
Devices with
KB5055523installed may receive a warning aboutWin32/ClickFix.ABAbeing present in the installer. To resolve this false positive, update Microsoft Security Intelligence to version 1.429.19.0 or later.DNS resolution may be broken when the following conditions are all true:
- WARP is in Secure Web Gateway without DNS filtering (tunnel-only) mode.
- A custom DNS server address is configured on the primary network adapter.
- The custom DNS server address on the primary network adapter is changed while WARP is connected.
To work around this issue, reconnect the WARP client by toggling off and back on.
A new GA release for the macOS WARP client is now available on the stable releases downloads page.
This release contains improvements and new exciting features, including post-quantum cryptography. By tunneling your corporate network traffic over Cloudflare, you can now gain the immediate protection of post-quantum cryptography without needing to upgrade any of your individual corporate applications or systems.
Changes and improvements
- Fixed an issue where WARP sometimes failed to automatically relaunch after updating.
- Fixed a device registration issue causing WARP connection failures when changing networks.
- Captive portal improvements and fixes:
- Captive portal sign in notifications will now be sent through operating system notification services.
- Fix for firewall configuration issue affecting clients in DoH only mode.
- Improved the connectivity status message in the client GUI.
- The WARP client now applies post-quantum cryptography end-to-end on enabled devices accessing resources behind a Cloudflare Tunnel. This feature can be enabled by MDM.
- Improvement to handle client configuration changes made by an MDM while WARP is not running.
- Fixed an issue affecting Split Tunnel Include mode, where traffic outside the tunnel was blocked when switching between Wi-Fi and Ethernet networks.
- Improvement for WARP connectivity issues on macOS due to the operating system not accepting DNS server configurations.
- Added a WARP client device posture check for SAN attributes to the client certificate check.
Known issues
- macOS Sequoia: Due to changes Apple introduced in macOS 15.0.x, the WARP client may not behave as expected. Cloudflare recommends the use of macOS 15.4 or later.
A new GA release for the Linux WARP client is now available on the stable releases downloads page.
This release contains improvements and new exciting features, including post-quantum cryptography. By tunneling your corporate network traffic over Cloudflare, you can now gain the immediate protection of post-quantum cryptography without needing to upgrade any of your individual corporate applications or systems.
Changes and improvements
- Fixed a device registration issue causing WARP connection failures when changing networks.
- Captive portal improvements and fixes:
- Captive portal sign in notifications will now be sent through operating system notification services.
- Fix for firewall configuration issue affecting clients in DoH only mode.
- Improved the connectivity status message in the client GUI.
- The WARP client now applies post-quantum cryptography end-to-end on enabled devices accessing resources behind a Cloudflare Tunnel. This feature can be enabled by MDM.
- Improvement to handle client configuration changes made by MDM while WARP is not running.
- Fixed an issue affecting Split Tunnel Include mode, where traffic outside the tunnel was blocked when switching between Wi-Fi and Ethernet networks.
- Added a WARP client device posture check for SAN attributes to the client certificate check.
Known issues
- Devices using WARP client 2025.4.929.0 and up may experience Local Domain Fallback failures if a fallback server has not been configured. To configure a fallback server, refer to Route traffic to fallback server.
The Email Routing platform supports SPF ↗ records and DKIM (DomainKeys Identified Mail) ↗ signatures and honors these protocols when the sending domain has them configured. However, if the sending domain doesn't implement them, we still forward the emails to upstream mailbox providers.
Starting on July 3, 2025, we will require all emails to be authenticated using at least one of the protocols, SPF or DKIM, to forward them. We also strongly recommend that all senders implement the DMARC protocol.
If you are using a Worker with an Email trigger to receive email messages and forward them upstream, you will need to handle the case where the forward action may fail due to missing authentication on the incoming email.
SPAM has been a long-standing issue with email. By enforcing mail authentication, we will increase the efficiency of identifying abusive senders and blocking bad emails. If you're an email server delivering emails to large mailbox providers, it's likely you already use these protocols; otherwise, please ensure you have them properly configured.
Magic Transit customers can now configure AS prepending on their BYOIP prefixes advertised at the Cloudflare edge. This allows for smoother traffic migration and minimizes packet loss when changing providers.
AS prepending makes the Cloudflare route less preferred by increasing the AS path length. You can use this to gradually shift traffic away from Cloudflare before withdrawing a prefix, avoiding abrupt routing changes.
Prepending can be configured via the API or through BGP community values when peering with the Magic Transit routing table. For more information, refer to Advertise prefixes.
We recently announced ↗ our public beta for remote bindings, which allow you to connect to deployed resources running on your Cloudflare account (like R2 buckets or D1 databases) while running a local development session.
Now, you can use remote bindings with your Next.js applications through the
@opennextjs/cloudflareadaptor ↗ by enabling the experimental feature in yournext.config.ts:initOpenNextCloudflareForDev();initOpenNextCloudflareForDev({experimental: { remoteBindings: true }});Then, all you have to do is specify which bindings you want connected to the deployed resource on your Cloudflare account via the
experimental_remoteflag in your binding definition:{"r2_buckets": [{"bucket_name": "testing-bucket","binding": "MY_BUCKET","experimental_remote": true,},],}[[r2_buckets]]bucket_name = "testing-bucket"binding = "MY_BUCKET"experimental_remote = trueYou can then run
next devto start a local development session (or start a preview withopennextjs-cloudflare preview), and all requests toenv.MY_BUCKETwill be proxied to the remotetesting-bucket— rather than the default local binding simulations.Remote bindings are also used during the build process, which comes with significant benefits for pages using Incremental Static Regeneration (ISR) ↗. During the build step for an ISR page, your server executes the page's code just as it would for normal user requests. If a page needs data to display (like fetching user info from KV), those requests are actually made. The server then uses this fetched data to render the final HTML.
Data fetching is a critical part of this process, as the finished HTML is only as good as the data it was built with. If the build process can't fetch real data, you end up with a pre-rendered page that's empty or incomplete.
With remote bindings support in OpenNext, your pre-rendered pages are built with real data from the start. The build process uses any configured remote bindings, and any data fetching occurs against the deployed resources on your Cloudflare account.
Want to learn more? Get started with remote bindings and OpenNext ↗.
Have feedback? Join the discussion in our beta announcement ↗ to share feedback or report any issues.
A new GA release for the Android Cloudflare One Agent is now available in the Google Play Store ↗. This release contains improvements and new exciting features, including post-quantum cryptography. By tunneling your corporate network traffic over Cloudflare, you can now gain the immediate protection of post-quantum cryptography ↗ without needing to upgrade any of your individual corporate applications or systems.
Changes and improvements
- QLogs are now disabled by default and can be enabled in the app by turning on Enable qlogs under Settings > Advanced > Diagnostics > Debug Logs. The QLog setting from previous releases will no longer be respected.
- DNS over HTTPS traffic is now included in the WARP tunnel by default.
- The WARP client now applies post-quantum cryptography ↗ end-to-end on enabled devices accessing resources behind a Cloudflare Tunnel. This feature can be enabled by MDM.
- Fixed an issue that caused WARP connection failures on ChromeOS devices.
A new GA release for the iOS Cloudflare One Agent is now available in the iOS App Store ↗. This release contains improvements and new exciting features, including post-quantum cryptography. By tunneling your corporate network traffic over Cloudflare, you can now gain the immediate protection of post-quantum cryptography ↗ without needing to upgrade any of your individual corporate applications or systems.
Changes and improvements
- QLogs are now disabled by default and can be enabled in the app by turning on Enable qlogs under Settings > Advanced > Diagnostics > Debug Logs. The QLog setting from previous releases will no longer be respected.
- DNS over HTTPS traffic is now included in the WARP tunnel by default.
- The WARP client now applies post-quantum cryptography ↗ end-to-end on enabled devices accessing resources behind a Cloudflare Tunnel. This feature can be enabled by MDM.
Workers can now talk to each other across separate dev commands using service bindings and tail consumers, whether started with
vite devorwrangler dev.Simply start each Worker in its own terminal:
Terminal window # Terminal 1vite dev# Terminal 2wrangler devThis is useful when different teams maintain different Workers, or when each Worker has its own build setup or tooling.
Check out the Developing with multiple Workers guide to learn more about the different approaches and when to use each one.
AI is supercharging app development for everyone, but we need a safe way to run untrusted, LLM-written code. We’re introducing Sandboxes ↗, which let your Worker run actual processes in a secure, container-based environment.
TypeScript import { getSandbox } from "@cloudflare/sandbox";export { Sandbox } from "@cloudflare/sandbox";export default {async fetch(request: Request, env: Env) {const sandbox = getSandbox(env.Sandbox, "my-sandbox");return sandbox.exec("ls", ["-la"]);},};exec(command: string, args: string[], options?: { stream?: boolean }):Execute a command in the sandbox.gitCheckout(repoUrl: string, options: { branch?: string; targetDir?: string; stream?: boolean }): Checkout a git repository in the sandbox.mkdir(path: string, options: { recursive?: boolean; stream?: boolean }): Create a directory in the sandbox.writeFile(path: string, content: string, options: { encoding?: string; stream?: boolean }): Write content to a file in the sandbox.readFile(path: string, options: { encoding?: string; stream?: boolean }): Read content from a file in the sandbox.deleteFile(path: string, options?: { stream?: boolean }): Delete a file from the sandbox.renameFile(oldPath: string, newPath: string, options?: { stream?: boolean }): Rename a file in the sandbox.moveFile(sourcePath: string, destinationPath: string, options?: { stream?: boolean }): Move a file from one location to another in the sandbox.ping(): Ping the sandbox.
Sandboxes are still experimental. We're using them to explore how isolated, container-like workloads might scale on Cloudflare — and to help define the developer experience around them.
You can try it today from your Worker, with just a few lines of code. Let us know what you build.
The new @cloudflare/actors ↗ library is now in beta!
The
@cloudflare/actorslibrary is a new SDK for Durable Objects and provides a powerful set of abstractions for building real-time, interactive, and multiplayer applications on top of Durable Objects. With beta usage and feedback,@cloudflare/actorswill become the recommended way to build on Durable Objects and draws upon Cloudflare's experience building products/features on Durable Objects.The name "actors" originates from the actor programming model, which closely ties to how Durable Objects are modelled.
The
@cloudflare/actorslibrary includes:- Storage helpers for querying embeddeded, per-object SQLite storage
- Storage helpers for managing SQL schema migrations
- Alarm helpers for scheduling multiple alarms provided a date, delay in seconds, or cron expression
Actorclass for using Durable Objects with a defined pattern- Durable Objects Workers API ↗ is always available for your application as needed
Storage and alarm helper methods can be combined with any Javascript class ↗ that defines your Durable Object, i.e, ones that extend
DurableObjectincluding theActorclass.JavaScript import { Storage } from "@cloudflare/actors/storage";export class ChatRoom extends DurableObject<Env> {storage: Storage;constructor(ctx: DurableObjectState, env: Env) {super(ctx, env)this.storage = new Storage(ctx.storage);this.storage.migrations = [{idMonotonicInc: 1,description: "Create users table",sql: "CREATE TABLE IF NOT EXISTS users (id INTEGER PRIMARY KEY)"}]}async fetch(request: Request): Promise<Response> {// Run migrations before executing SQL queryawait this.storage.runMigrations();// Query with SQL templatelet userId = new URL(request.url).searchParams.get("userId");const query = this.storage.sql`SELECT * FROM users WHERE id = ${userId};`return new Response(`${JSON.stringify(query)}`);}}@cloudflare/actorslibrary introduces theActorclass pattern.Actorlets you access Durable Objects without writing the Worker that communicates with your Durable Object (the Worker is created for you). By default, requests are routed to a Durable Object named "default".JavaScript export class MyActor extends Actor<Env> {async fetch(request: Request): Promise<Response> {return new Response('Hello, World!')}}export default handler(MyActor);You can route to different Durable Objects by name within your
Actorclass usingnameFromRequest↗.JavaScript export class MyActor extends Actor<Env> {static nameFromRequest(request: Request): string {let url = new URL(request.url);return url.searchParams.get("userId") ?? "foo";}async fetch(request: Request): Promise<Response> {return new Response(`Actor identifier (Durable Object name): ${this.identifier}`);}}export default handler(MyActor);For more examples, check out the library README ↗.
@cloudflare/actorslibrary is a place for more helpers and built-in patterns, like retry handling and Websocket-based applications, to reduce development overhead for common Durable Objects functionality. Please share feedback and what more you would like to see on our Discord channel ↗.
Zero Trust now includes Data security analytics, providing you with unprecedented visibility into your organization sensitive data.
The new dashboard includes:
-
Sensitive Data Movement Over Time:
- See patterns and trends in how sensitive data moves across your environment. This helps understand where data is flowing and identify common paths.
-
Sensitive Data at Rest in SaaS & Cloud:
- View an inventory of sensitive data stored within your corporate SaaS applications (for example, Google Drive, Microsoft 365) and cloud accounts (such as AWS S3).
-
DLP Policy Activity:
- Identify which of your Data Loss Prevention (DLP) policies are being triggered most often.
- See which specific users are responsible for triggering DLP policies.
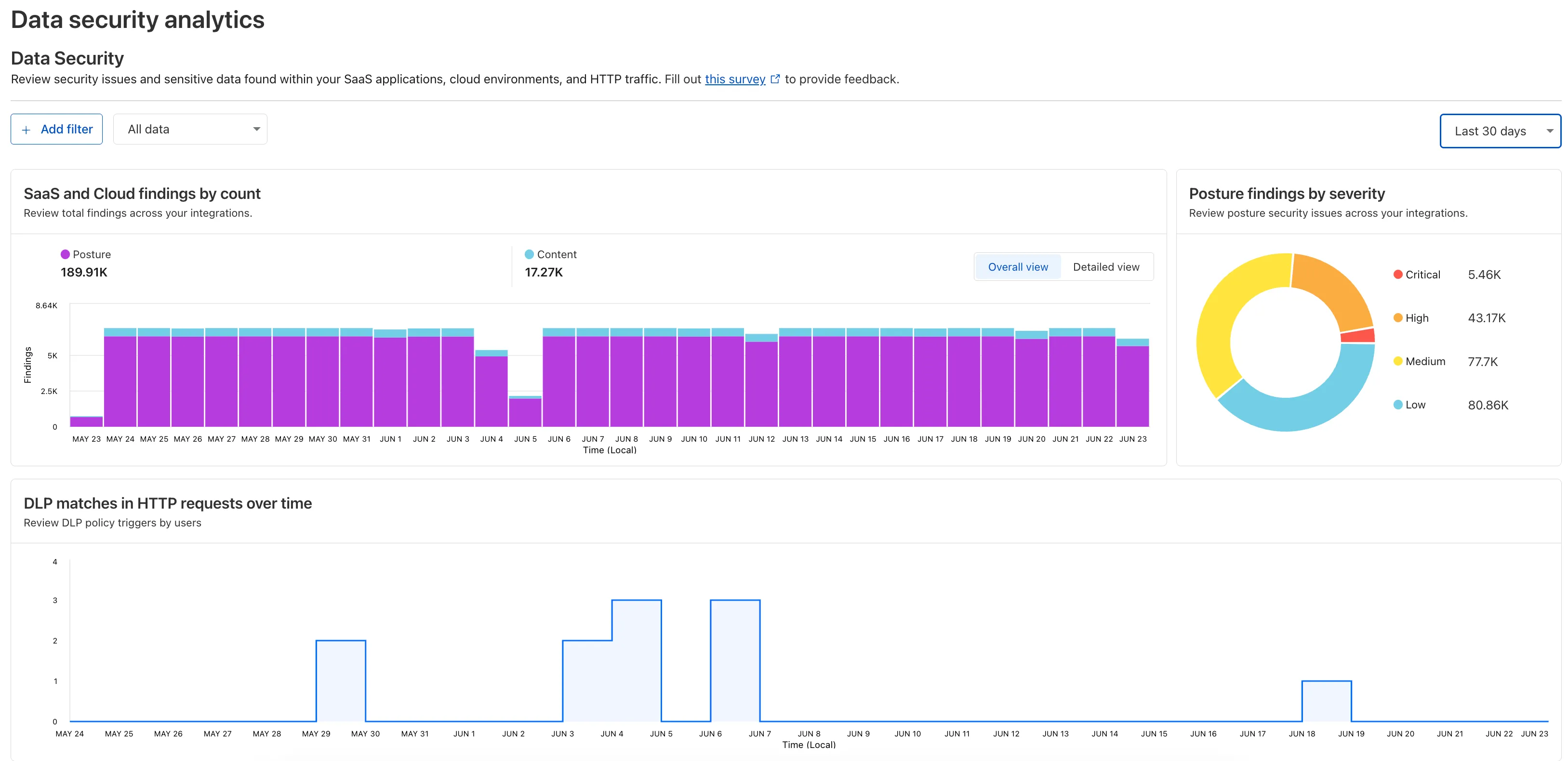
To access the new dashboard, log in to Cloudflare One ↗ and go to Insights on the sidebar.
-
We're announcing the GA of User Groups for Cloudflare Dashboard and System for Cross Domain Identity Management (SCIM) User Groups, strengthening our RBAC capabilities with stable, production-ready primitives for managing access at scale.
What's New
User Groups [GA]: User Groups are a new Cloudflare IAM primitive that enable administrators to create collections of account members that are treated equally from an access control perspective. User Groups can be assigned permission policies, with individual members in the group inheriting all permissions granted to the User Group. User Groups can be created manually or via our APIs.
SCIM User Groups [GA]: Centralize & simplify your user and group management at scale by syncing memberships directly from your upstream identity provider (like Okta or Entra ID) to the Cloudflare Platform. This ensures Cloudflare stays in sync with your identity provider, letting you apply Permission Policies to those synced groups directly within the Cloudflare Dashboard.
Stability & Scale: These features have undergone extensive testing during the Public Beta period and are now ready for production use across enterprises of all sizes.
For more info:
Customers using Cloudflare Network Interconnect with the 1.x dataplane can now subscribe to maintenance alert emails. These alerts notify you of planned maintenance windows that may affect your CNI circuits.
For more information, refer to Monitoring and alerts.
We’ve increased the total allowed size of
blobfields on data points written to Workers Analytics Engine from 5 KB to 16 KB.This change gives you more flexibility when logging rich observability data — such as base64-encoded payloads, AI inference traces, or custom metadata — without hitting request size limits.
You can find full details on limits for queries, filters, payloads, and more here in the Workers Analytics Engine limits documentation.
JavaScript export default {async fetch(request, env) {env.analyticsDataset.writeDataPoint({// The sum of all of the blob's sizes can now be 16 KBblobs: [// The URL of the request to the Workerrequest.url,// Some metadata about your application you'd like to storeJSON.stringify(metadata),// The version of your Worker this datapoint was collected fromenv.versionMetadata.tag,],indexes: ["sample-index"],});},};TypeScript export default {async fetch(request, env) {env.analyticsDataset.writeDataPoint({// The sum of all of the blob's sizes can now be 16 KBblobs: [// The URL of the request to the Workerrequest.url,// Some metadata about your application you'd like to storeJSON.stringify(metadata),// The version of your Worker this datapoint was collected fromenv.versionMetadata.tag,],indexes: ["sample-index"],});}};
In AutoRAG, you can now view your object's custom metadata in the response from
/searchand/ai-search, and optionally add acontextfield in the custom metadata of an object to provide additional guidance for AI-generated answers.You can add custom metadata to an object when uploading it to your R2 bucket.
When you run a search, AutoRAG now returns any custom metadata associated with the object. This metadata appears in the response inside
attributesthenfile, and can be used for downstream processing.For example, the
attributessection of your search response may look like:{"attributes": {"timestamp": 1750001460000,"folder": "docs/","filename": "launch-checklist.md","file": {"url": "https://wiki.company.com/docs/launch-checklist","context": "A checklist for internal launch readiness, including legal, engineering, and marketing steps."}}}When you include a custom metadata field named
context, AutoRAG attaches that value to each chunk of the file. When you run an/ai-searchquery, thiscontextis passed to the LLM and can be used as additional input when generating an answer.We recommend using the
contextfield to describe supplemental information you want the LLM to consider, such as a summary of the document or a source URL. If you have several different metadata attributes, you can join them together however you choose within thecontextstring.For example:
{"context": "summary: 'Checklist for internal product launch readiness, including legal, engineering, and marketing steps.'; url: 'https://wiki.company.com/docs/launch-checklist'"}This gives you more control over how your content is interpreted, without requiring you to modify the original contents of the file.
Learn more in AutoRAG's metadata filtering documentation.
In AutoRAG, you can now filter by an object's file name using the
filenameattribute, giving you more control over which files are searched for a given query.This is useful when your application has already determined which files should be searched. For example, you might query a PostgreSQL database to get a list of files a user has access to based on their permissions, and then use that list to limit what AutoRAG retrieves.
For example, your search query may look like:
JavaScript const response = await env.AI.autorag("my-autorag").search({query: "what is the project deadline?",filters: {type: "eq",key: "filename",value: "project-alpha-roadmap.md",},});This allows you to connect your application logic with AutoRAG's retrieval process, making it easy to control what gets searched without needing to reindex or modify your data.
Learn more in AutoRAG's metadata filtering documentation.
Authoritative DNS analytics are now available on the account level via the Cloudflare GraphQL Analytics API.
This allows users to query DNS analytics across multiple zones in their account, by using the
accountsfilter.Here is an example to retrieve the most recent DNS queries across all zones in your account that resulted in an
NXDOMAINresponse over a given time frame. Please replacea30f822fcd7c401984bf85d8f2a5111cwith your actual account ID.GraphQL example for account-level DNS analytics query GetLatestNXDOMAINResponses {viewer {accounts(filter: { accountTag: "a30f822fcd7c401984bf85d8f2a5111c" }) {dnsAnalyticsAdaptive(filter: {date_geq: "2025-06-16"date_leq: "2025-06-18"responseCode: "NXDOMAIN"}limit: 10000orderBy: [datetime_DESC]) {zoneTagqueryNameresponseCodequeryTypedatetime}}}}To learn more and get started, refer to the DNS Analytics documentation.
-
We've simplified the programmatic deployment of Workers via our Cloudflare SDKs. This update abstracts away the low-level complexities of the
multipart/form-dataupload process, allowing you to focus on your code while we handle the deployment mechanics.This new interface is available in:
- cloudflare-typescript ↗ (4.4.1)
- cloudflare-python ↗ (4.3.1)
For complete examples, see our guide on programmatic Worker deployments.
Previously, deploying a Worker programmatically required manually constructing a
multipart/form-dataHTTP request, packaging your code and a separatemetadata.jsonfile. This was more complicated and verbose, and prone to formatting errors.For example, here's how you would upload a Worker script previously with cURL:
Terminal window curl https://api.cloudflare.com/client/v4/accounts/<account_id>/workers/scripts/my-hello-world-script \-X PUT \-H 'Authorization: Bearer <api_token>' \-F 'metadata={"main_module": "my-hello-world-script.mjs","bindings": [{"type": "plain_text","name": "MESSAGE","text": "Hello World!"}],"compatibility_date": "$today"};type=application/json' \-F 'my-hello-world-script.mjs=@-;filename=my-hello-world-script.mjs;type=application/javascript+module' <<EOFexport default {async fetch(request, env, ctx) {return new Response(env.MESSAGE, { status: 200 });}};EOFWith the new SDK interface, you can now define your entire Worker configuration using a single, structured object.
This approach allows you to specify metadata like
main_module,bindings, andcompatibility_dateas clearer properties directly alongside your script content. Our SDK takes this logical object and automatically constructs the complex multipart/form-data API request behind the scenes.Here's how you can now programmatically deploy a Worker via the
cloudflare-typescriptSDK ↗JavaScript import Cloudflare from "cloudflare";import { toFile } from "cloudflare/index";// ... client setup, script content, etc.const script = await client.workers.scripts.update(scriptName, {account_id: accountID,metadata: {main_module: scriptFileName,bindings: [],},files: {[scriptFileName]: await toFile(Buffer.from(scriptContent), scriptFileName, {type: "application/javascript+module",}),},});TypeScript import Cloudflare from 'cloudflare';import { toFile } from 'cloudflare/index';// ... client setup, script content, etc.const script = await client.workers.scripts.update(scriptName, {account_id: accountID,metadata: {main_module: scriptFileName,bindings: [],},files: {[scriptFileName]: await toFile(Buffer.from(scriptContent), scriptFileName, {type: 'application/javascript+module',}),},});View the complete example here: https://github.com/cloudflare/cloudflare-typescript/blob/main/examples/workers/script-upload.ts ↗
We've also made several fixes and enhancements to the Cloudflare Terraform provider ↗:
- Fixed the
cloudflare_workers_script↗ resource in Terraform, which previously was producing a diff even when there were no changes. Now, yourterraform planoutputs will be cleaner and more reliable. - Fixed the
cloudflare_workers_for_platforms_dispatch_namespace↗, where the provider would attempt to recreate the namespace on aterraform apply. The resource now correctly reads its remote state, ensuring stability for production environments and CI/CD workflows. - The
cloudflare_workers_route↗ resource now allows for thescriptproperty to be empty, null, or omitted to indicate that pattern should be negated for all scripts (see routes docs). You can now reserve a pattern or temporarily disable a Worker on a route without deleting the route definition itself. - Using
primary_location_hintin thecloudflare_d1_database↗ resource will no longer always try to recreate. You can now safely change the location hint for a D1 database without causing a destructive operation.
We've also properly documented the Workers Script And Version Settings in our public OpenAPI spec and SDKs.
Gateway will now evaluate Network (Layer 4) policies before HTTP (Layer 7) policies. This change preserves your existing security posture and does not affect which traffic is filtered — but it may impact how notifications are displayed to end users.
This change will roll out progressively between July 14–18, 2025. If you use HTTP policies, we recommend reviewing your configuration ahead of rollout to ensure the user experience remains consistent.
Previous order:
- DNS policies
- HTTP policies
- Network policies
New order:
- DNS policies
- Network policies
- HTTP policies
This change may affect block notifications. For example:
- You have an HTTP policy to block
example.comand display a block page. - You also have a Network policy to block
example.comsilently (no client notification).
With the new order, the Network policy will trigger first — and the user will no longer see the HTTP block page.
To ensure users still receive a block notification, you can:
- Add a client notification to your Network policy, or
- Use only the HTTP policy for that domain.
This update is based on user feedback and aims to:
- Create a more intuitive model by evaluating network-level policies before application-level policies.
- Minimize 526 connection errors by verifying the network path to an origin before attempting to establish a decrypted TLS connection.
To learn more, visit the Gateway order of enforcement documentation.
Log Explorer is now GA, providing native observability and forensics for traffic flowing through Cloudflare.
Search and analyze your logs, natively in the Cloudflare dashboard. These logs are also stored in Cloudflare's network, eliminating many of the costs associated with other log providers.
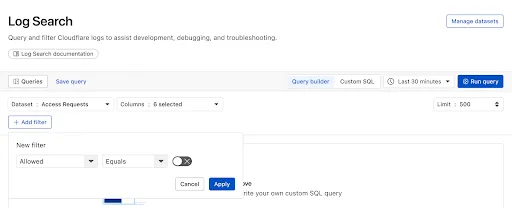
With Log Explorer, you can now:
- Monitor security and performance issues with custom dashboards – use natural language to define charts for measuring response time, error rates, top statistics and more.
- Investigate and troubleshoot issues with Log Search – use data type-aware search filters or custom sql to investigate detailed logs.
- Save time and collaborate with saved queries – save Log Search queries for repeated use or sharing with other users in your account.
- Access Log Explorer at the account and zone level – easily find Log Explorer at the account and zone level for querying any dataset.
For help getting started, refer to our documentation.
Today we announced the public beta ↗ of remote bindings for local development. With remote bindings, you can now connect to deployed resources like R2 buckets and D1 databases while running Worker code on your local machine. This means you can test your local code changes against real data and services, without the overhead of deploying for each iteration.
To enable remote mode, add
"experimental_remote" : trueto each binding that you want to rely on a remote resource running on Cloudflare:{"name": "my-worker",// Set this to today's date"compatibility_date": "2026-03-12","r2_buckets": [{"bucket_name": "screenshots-bucket","binding": "screenshots_bucket","experimental_remote": true,},],}name = "my-worker"# Set this to today's datecompatibility_date = "2026-03-12"[[r2_buckets]]bucket_name = "screenshots-bucket"binding = "screenshots_bucket"experimental_remote = trueWhen remote bindings are configured, your Worker still executes locally, but all binding calls are proxied to the deployed resource that runs on Cloudflare's network.
You can try out remote bindings for local development today with:
- Wrangler v4.20.3: Use the
wrangler dev --x-remote-bindingscommand. - The Cloudflare Vite Plugin: Refer to the documentation for how to enable in your Vite config.
- The Cloudflare Vitest Plugin: Refer to the documentation for how to enable in your Vitest config.
Have feedback? Join the discussion in our beta announcement ↗ to share feedback or report any issues.
- Wrangler v4.20.3: Use the